The programming world is turning more and more functional. While pure functional programming languages like Haskell are yet to become mainstream, many of its tenets such as higher order functions and immutable data are – one indication being the additon of lambda functions in languages such as Java 8 and ECMA Script 2015.
Another example at the architectural level is the rise of CQRS and Event Sourcing as an alternative to traditional CRUD data models backed by relational or NoSQL databases. To understand why, let’s first take a deeper look at the traditional alternative – using a single data store with an n-tier architecture.
Traditional n-tier architecture with CRUD

N-tier architecture
The n-tier architecture, or variations thereof, is the go-to pattern for any data centric application, from a local desktop application to an online only SaaS solution. The idea is simple – use separation of concern to keep presentation, business logic and data persistence neatly separated from each other. The data tier is responsible for writing to and reading from a data store, leaving the other layers (in theory) blissfully unaware of the mechanisms used to actually persist and retrieve data. A data layer may expose a domain model – an attempt to encode the entities that the system deals with in terms of data types with well defined relationships (a “user” can be linked to many “accounts” and has a single instance of “preferences”). Often modifications of data is expressed simply in terms of the C, R and D of CRUD (create, update and delete), and programming platforms may even expose various forms of scaffolding to generate the code required for these operations automatically (see examples in Ruby on Rails and .NET).
So what’s wrong with that? This model is so common that the majority of people never look for an alternative, and for simple applications it may never cause any problems. Once you start to scratch the surface however, applications tend to not actually support updating of entities without interfering. A User object may have an id, or creation time, or other generated data present when the entity is read, but the data layer will not allow you to update yourself. Likewise, different users may have permission to only update parts of an entity, or only see parts of an entity, either requiring the data layer to expose more fine grained operations that do not accept an entire domain object, to prevent certain fields to be set in certain circumstances, or to ignore certain fields altogether.
Writing and reading data are different things
In fact, writing data and reading data generally have vastly different areas of concern:
| Writing | Reading |
|---|---|
| Enforcing data integrity | Perform efficient searches and lookups |
| Providing atomic updates / transactions | Calculate derived values (sums etc) |
| Facilitating version control (optimistic concurrency or locking) | Provide multiple views of data |
| Enforcing write permissions | Enforce row and column level permissions |
Different storage engines have different biases towards facilitating writing or reading. For example, a traditional SQL database is very good at enforcing data integrity through foreign keys and other constraints, while NoSQL databases may sacrifice these built-in guard rails for higher throughput and better scalability. Likewise, the data layer may choose to optimize for one over the other and pre-compute values to make them readily available to read operations (“number of visits to the website per day”). While providers of different storage solutions will boast about their features and claim that their product will solve all your storage needs, the truth is – the choice of storage engine and data layer design in a traditional CRUD model always boils down to a compromise between what is in reality very different concerns.
Enter CQRS
The above paints a very bleak picture, and hints at there being an alternative: enter CQRS – Command Query Responsibility Segregation. CQRS, in contrast with CRUD, starts with the observation that reading and writing data are very different things. In CQRS terminology, operations on a datastore can be divided into Commands (operations that modify data) and Queries (operations that read data). Commands do not typically return data to the caller beyond success or failure, and Queries are guaranteed to be idempotent – they can be retried multiple times with the same result (assuming no commands have taken place). In REST terminology, commands are PUTs or POSTs, while queries are GETs.
A naive implementation of CQRS would simply make create, update and delete commands, but this is missing the point. Explicitly separating commands as “something other” than the data model used for reading means that a User as we see it when querying for data does not have to be the same as that used in a command. Rather than thinking in terms of updating a user, we can think in terms of a “change email address” command or a “change billing details” command. In this model there is no longer any confusion about with fields of an entity that are updatable or generated, each command contains exactly the fields that are relevant to it. Permissions also become easier, instead of checking whether a caller is attempting to set sensitive fields of an entity, the implementation can simply check if the user has permission to execute a particular type of command.
CQRS can be implemented with a shared data store behind the scenes, hiding the details behind a facade of commands and queries, or with separate data models altogether, each optimised for the concerns of commands or queries.
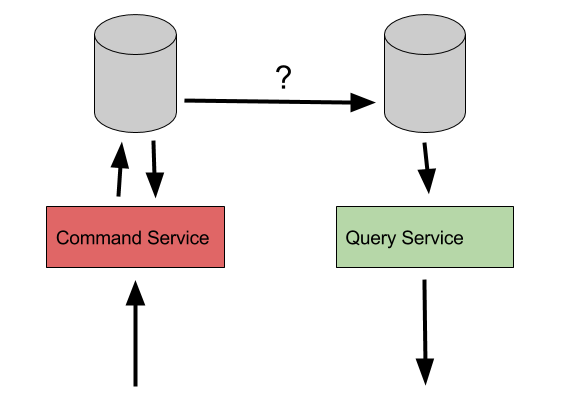
CQRS – multiple data stores
However, we now appear to be back to square one. We have a representation of our data model suitable for commands, and a representation suitable for queries, but no way yet of populating one with data from the other. What we are looking for is a method by which we can represent data in more than one way, while preserving data integrity, and keep a single source of truth – we want to have our CQRS cake and eat it too.
Adding Event Sourcing
Enter Event Sourcing. While event sourcing works very well in conjunction with CQRS, it is a pattern in its own right and used behind the scenes in many of the pieces of software that we use daily, including file systems and (maybe not surprisingly), database engines. The best mental model of how event sourcing works may be to compare it to accounting. In good accounting practices, there is an append only ledger of incoming and outgoing transactions (sales, purchases etc). When a new transaction is made, a new entry is added to the ledger and the current balance of an account is calculating as a function of all transactions as needed. Compare this with a CRUD model of an account with a single balance that gets added to or subtracted from and you may start to see some of the advantages of this pattern.
An event is related to a command in CQRS, but while a command is the expression of an intent or wish that may be rejected, an event is a fact that has happened. If a command is executed to update the email address of a user, the event may be “email address updated”. The relationship between a command and the related events may not be so obvious however, a command to update the address of a user may result in an event that contains a lat/long approximate location of the address, information that wasn’t present in the command itself.
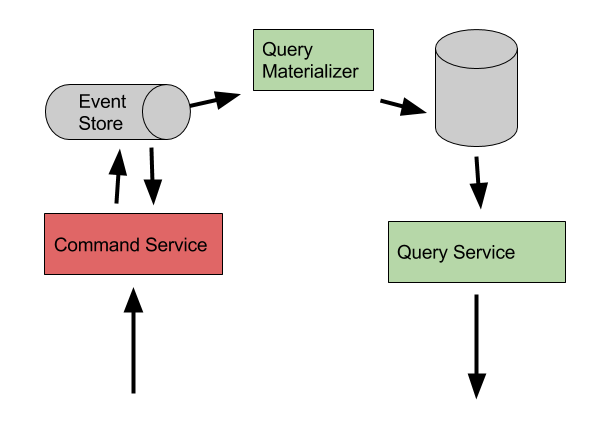
CQRS with Event Sourcing
A storage engine optimised for handling event streams gives us the missing piece of the puzzle, one such product being EventStore. EventStore handles immutable, append only streams of events and also acts as a message bus, allowing other services in a system to respond to new events in real time as they are persisted. Using this or a similar product, the query model can update its own storage from the events, much in the same way in which a database would be updated in the case of CQRS with a shared data store, but with one important difference: As events are being consumed (remember, events are historical facts), the query model no longer need to concern itself with permissions, validation, and data integrity enforcement. It is free to store data in the form most suitable to its own needs, and pre-compute any values that may be of interest to it. Need to update a full text search index in addition to saving to a SQL database? No problem! Need to save not just one version of the entity but two, one for internal admin users and one with only the information that should be shared with external parties? Go right ahead.
In fact, having multiple views of the same entity is a pattern that can be taken one step further. Instead of having a single query model kept in sync with the updates, there can be many – each optimised for its particular use case – for example viewing details of individual users vs generating reports on active users per day. The event stream forms the source of truth and query models are simply convenient representations that can be created and re-created as needed.
Other benefits of event sourcing
While event sourcing provides an excellent mechanism for synchronising one or more query data models with a command data model, it also comes with a number of other indirect benefits:
- Provably correct audit log. As all changes are persisted in the form of events, there is a clear trail of updates made to any piece of data in the system. Events can be annotated with information about who performed or requested the change and additional metadata such as network addresses involved. While these audit trails can be produced “on the side” in a traditional CRUD architecture, it is difficult to prove that the changes logged are actually the changes made to the underlying data store.
- Opportunity to create query models from historical data. Events describe the entire history of a given entity, and not just the current state. As such, it is possible to create reports and query models from aspects of the events that were never originally planned for. While a traditional CRUD entity often includes a “last update time”, an event sourced model makes it possible to derive the timestamp of each update, or even the state of the entity at any given point in time in the past.
- Decoupled side-effects. A command service that emits events can be decoupled from any logic intended to happen on certain changes. If your system should send a welcome email when they provide an email address, this can be done in response to a “email updated” event, rather than as part of the logic in charge of persisting the new email.
- Assisted troubleshooting and debugging. Trying to reproduce a bug that happened in production? Rather than having to re-do all the actions made to the live system to attempt to get it into the same state, you can copy and re-play the events and see exactly how the system behaves. Similarly, automated testing can use a real event log and prove that the result is as expected after any changes.
Elder Sourcerer – a framework for implementing CQRS with event sourcing
At Elder, we are using the architecture outline above and have recently released our framework Sourcerer under an MIT license. Sourcerer provides the building blocks required to implement CQRS with event sourcing in Java 8, and does much of the heavy lifting. It is used together with EventStore, but designed to be storage agnostic. For more information, see Elder Open Source Software at GitHub or contact tech at elder dot org.
API Developer Weekly #141 | Restlet - We Know About APIs
May I simply say what a relief to find somebody that truly
knows what they are talking about on the net.
You certainly realize how to bring an issue to light and make it important.
More people should look at this and understand this side of your story.
It’s surprising you’re not more popular given that you surely have
the gift.
Thank you for every other great article. Where
else may just anybody get that kind of info
in such an ideal approach of writing? I’ve a presentation subsequent week, and I’m at the look for such info.